JangHan Park
Software Engineer, Photographer, Cat Lover.
San Jose, CA, USA, Earth
Chat
Chat
Ask Me Anything
LinkedIn
LinkedIn
Experience & updates
Blog
Blog
Notes
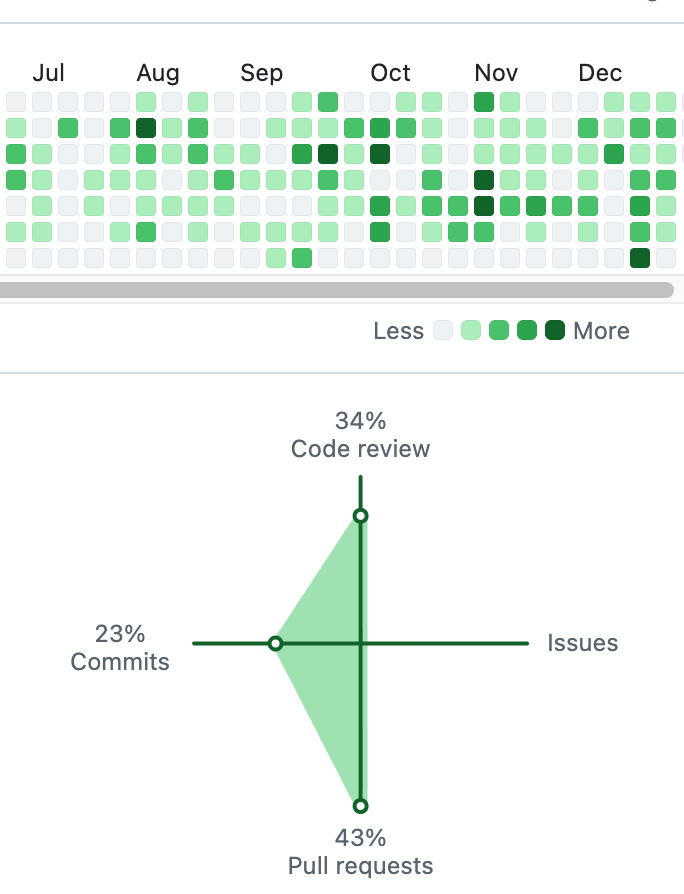
GitHub
GitHub
Projects & experiments
Photos
Google Photos
Albums & snapshots
Social
Instagram
Moments & stories